Quasirandom simulation uses low-discrepancy or quasirandom sequences in place of pseudorandom sequences, producing faster convergence in problems of moderate dimensions. The objective of this article is both pedagogical and practical: to provide an easily understood introduction to the construction of Sobol sequences and a toolkit for constructing and evaluating such sequences.
Introduction
In the eighteenth century, Georges-Louis Leclerc, Comte de Buffon, proposed a novel method to estimate ![]() —dropping a needle over and over again onto a wooden floor of parallel planks. The probability of a needle crossing a join in the floor is related to
—dropping a needle over and over again onto a wooden floor of parallel planks. The probability of a needle crossing a join in the floor is related to ![]() . By counting the number of crosses, one can estimate this probability, and hence compute a value for
. By counting the number of crosses, one can estimate this probability, and hence compute a value for ![]() (see [1]). Buffon is said to have tried the method by tossing baguettes over his shoulder. A more direct way of estimating
(see [1]). Buffon is said to have tried the method by tossing baguettes over his shoulder. A more direct way of estimating ![]() is to throw darts randomly at a circular target inscribed in a square, and count the proportion that land inside the circle. These are simple examples of numerical integration by simulation.
is to throw darts randomly at a circular target inscribed in a square, and count the proportion that land inside the circle. These are simple examples of numerical integration by simulation.

Numerical integration requires evaluating a function at a number of distinct points and computing an average value. There are at least three ways in which we could lay out a grid of points on which to evaluate an integral, which are illustrated below. Familiar rules of quadrature, such as Simpson’s rule, use a regular grid or lattice. The shortcoming of this approach is that it is difficult to compute a sufficiently dense grid in higher dimensions. For example, a grid of four points in 250 dimensions requires ![]() points. Furthermore, only a limited number of coordinate values are evaluated. Traditional Monte Carlo simulation uses a pseudorandom grid, so that numerous combinations of points are evaluated. We observe that the points tend to cluster, with many boxes having no points while some boxes have multiple points. Low-discrepancy or quasirandom sequences attempt to combine the best features of both a grid and pseudorandom points while overcoming the disadvantages of each. They are specifically constructed so that they fill the space in a “quasi” random but uniform manner. Observe that each of the boxes in the right-hand graph has one and only one point.
points. Furthermore, only a limited number of coordinate values are evaluated. Traditional Monte Carlo simulation uses a pseudorandom grid, so that numerous combinations of points are evaluated. We observe that the points tend to cluster, with many boxes having no points while some boxes have multiple points. Low-discrepancy or quasirandom sequences attempt to combine the best features of both a grid and pseudorandom points while overcoming the disadvantages of each. They are specifically constructed so that they fill the space in a “quasi” random but uniform manner. Observe that each of the boxes in the right-hand graph has one and only one point.

The most common pseudorandom number generator is the linear congruential generator, in which successive numbers are generated recursively by
| (1) |
starting with an initial seed ![]() . Dividing by
. Dividing by ![]() gives a sequence of fractions
gives a sequence of fractions ![]() in the unit interval
in the unit interval ![]() . By careful choice of
. By careful choice of ![]() ,
, ![]() , and
, and ![]() , a sequence of period
, a sequence of period ![]() can be obtained. The resulting sequence of real numbers will appear to be uniformly distributed on
can be obtained. The resulting sequence of real numbers will appear to be uniformly distributed on ![]() . For simulation, it is not sufficient to avoid clustering in a single dimension. Most practical problems, from estimating
. For simulation, it is not sufficient to avoid clustering in a single dimension. Most practical problems, from estimating ![]() to valuing an exotic financial derivative, require multidimensional random sequences. In the center of the previous figure, we observe the clustering that is typical of pseudorandom sequences.
to valuing an exotic financial derivative, require multidimensional random sequences. In the center of the previous figure, we observe the clustering that is typical of pseudorandom sequences.
Low-discrepancy sequences are known to give superior performance in low-dimensional problems, but their relative advantage erodes as the dimension of the integral increases. One practical area in which quasirandom simulation has shown great promise is finance, where valuation of derivative instruments requires the computation of multidimensional expected values. Such valuations may need to be computed daily, which means that computational efficiency is extremely important. In this application, low-discrepancy sequences have been shown to give improved performance even in very high-dimensional problems.
Low-discrepancy sequences have been proposed by Halton, Faure, Sobol, and Niederreiter. Though not exhibiting the lowest asymptotic discrepancy, Sobol sequences have been found in practice to yield as good or better performance, especially in financial applications. Consequently, this article focuses on Sobol sequences, although the tools are more generally applicable. The objective of this article is both pedagogical and practical: to provide an easily understood introduction to the composition of Sobol sequences and a toolkit for constructing and evaluating such sequences.
The Construction of Sobol Sequences
A Sobol sequence is a sequence of points ![]() in the unit hypercube
in the unit hypercube ![]() , where
, where ![]() is the dimension of the problem. In other words, each element
is the dimension of the problem. In other words, each element ![]() of the sequence is a
of the sequence is a ![]() -dimensional vector whose components are fractions between 0 and 1. A Sobol sequence can be computed by the simple recursion
-dimensional vector whose components are fractions between 0 and 1. A Sobol sequence can be computed by the simple recursion
| (2) |
Equation (2) is analogous to the linear congruential generator (1) for pseudorandom numbers. The differences are:
- The coefficients
 vary with
vary with  and also with the dimension
and also with the dimension  (as
(as  is a vector).
is a vector). - The operator
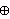 is bitwise exclusive or rather than multiplication. It is equivalent to addition modulo 2.
is bitwise exclusive or rather than multiplication. It is equivalent to addition modulo 2.
The coefficients ![]() are known as direction numbers. The index
are known as direction numbers. The index ![]() of the appropriate element of the set of direction numbers is the rightmost zero bit in the binary expansion of
of the appropriate element of the set of direction numbers is the rightmost zero bit in the binary expansion of ![]() . Consequently, to produce a Sobol sequence of length
. Consequently, to produce a Sobol sequence of length ![]() requires one direction number for each bit in the binary expansion of
requires one direction number for each bit in the binary expansion of ![]() , a total of
, a total of ![]() direction numbers for each dimension. The complicated part of computing a Sobol sequence is computing the direction numbers for each dimension. Once this is done, computing the series using (2) is straightforward and fast. First, we load the accompanying package, assuming that it is in the current directory or a directory in the path.
direction numbers for each dimension. The complicated part of computing a Sobol sequence is computing the direction numbers for each dimension. Once this is done, computing the series using (2) is straightforward and fast. First, we load the accompanying package, assuming that it is in the current directory or a directory in the path.
![]()
The sequence ![]() is a valid set of direction numbers for generating the first 63 elements of a one-dimensional Sobol sequence. Here are the first 16 elements of this sequence.
is a valid set of direction numbers for generating the first 63 elements of a one-dimensional Sobol sequence. Here are the first 16 elements of this sequence.
![]()
![]()
The seventh element in this sequence is ![]() . The binary expansion of 7 is
. The binary expansion of 7 is ![]() ; the rightmost zero bit is four from the end. Therefore the appropriate direction number is the fourth, namely
; the rightmost zero bit is four from the end. Therefore the appropriate direction number is the fourth, namely ![]() . From (2), the eighth element is
. From (2), the eighth element is
![]()
We now turn to the computation of direction numbers, the essential ingredients of a Sobol sequence. A degree ![]() polynomial
polynomial
![]()
defines a unique recursive sequence of order ![]()
![]()
requiring ![]() initial values. Direction numbers for a Sobol sequence are computed by a special recursive sequence
initial values. Direction numbers for a Sobol sequence are computed by a special recursive sequence
![]()
such that:
- The class of polynomials is restricted to the primitive polynomials mod 2 (defined in the next section).
- Addition (+) is replaced with bitwise or ().
- An extra term is added.
Computationally, it is convenient to use the equivalent recursion, which requires only integer arithmetic:
| (3) |
Seeded with ![]() non-negative odd integers
non-negative odd integers ![]() with
with ![]() , subsequent values generated by (3) are also non-negative odd integers with
, subsequent values generated by (3) are also non-negative odd integers with ![]() for all
for all ![]() . Direction numbers are obtained by dividing each term by
. Direction numbers are obtained by dividing each term by ![]() , that is
, that is
![]()
To illustrate, the direction numbers used above were generated from the third-degree primitive polynomial ![]() , in which
, in which ![]() and
and ![]() . The corresponding recurrence relation is
. The corresponding recurrence relation is
![]()
Starting with the initial values ![]() , this recurrence generates the sequence
, this recurrence generates the sequence ![]() , which consists of the numerators of the direction numbers used above.
, which consists of the numerators of the direction numbers used above.

![]()
Each dimension of the Sobol sequence requires a different primitive polynomial, and each degree ![]() polynomial requires
polynomial requires ![]() initial values, odd integers less than
initial values, odd integers less than ![]() , respectively. The choice of initial values is the one area of discretion left to the modeler. Indeed, the choice of initial values is the most important issue in successful application of Sobol sequences.
, respectively. The choice of initial values is the one area of discretion left to the modeler. Indeed, the choice of initial values is the most important issue in successful application of Sobol sequences.
Consequently, a toolbox for quasirandom simulation using Sobol sequences needs to provide for the following:
- identifying primitive polynomials modulo 2 to specify the recursions for generating direction numbers
- selecting appropriate initial values to seed the recursions
- computing the direction numbers
- generating the resulting multidimensional Sobol sequence
These ingredients are depicted schematically in the following diagram.

In addition, our toolbox provides functions for computing the discrepancy on any sequence, which can be used to evaluate initial values for computing Sobol sequences and to compare the effectiveness of pseudorandom and quasirandom sequences.
Primitive Polynomials Mod 2
A polynomial modulo 2 is a polynomial
![]()
whose coefficients ![]() are either zero or one. The highest power is the degree of the polynomial. There are
are either zero or one. The highest power is the degree of the polynomial. There are ![]() third-degree polynomials mod 2, namely
third-degree polynomials mod 2, namely
![]()
The term primitive polynomial has two distinct meanings in algebra (see [2]). For our purposes, a polynomial mod 2 is primitive if (in binary arithmetic):
- it is irreducible (cannot be factored)
- the smallest power
 for which the polynomial divides
for which the polynomial divides  is
is 
Only two of the eight third-degree polynomials are primitive, namely
![]()
Note that a polynomial with no constant term can always be factored as
![]()
Therefore, every primitive polynomial has a constant term. For the rest of this article, polynomial means polynomial modulo 2.
Encoding
Any polynomial mod 2 can be uniquely encoded as an integer by interpreting the coefficients (0 or 1) as bits. For example, the primitive third-degree polynomial ![]() can be encoded as binary
can be encoded as binary ![]() or decimal 11. The Mathematica functions EncodeP and DecodeP encode and decode polynomials.
or decimal 11. The Mathematica functions EncodeP and DecodeP encode and decode polynomials.
The two primitive third-degree polynomials are encoded.
![]()
![]()
They can be decoded.
![]()
![]()
For the remainder of the article, we will call a polynomial’s unique decimal code its ![]() -number.
-number.
Polynomials of Degree 
A polynomial with ![]() -number
-number ![]() is of degree
is of degree ![]() if and only if
if and only if ![]() . This provides a very straightforward method for generating all the polynomials of a given degree, namely by decoding the consecutive integers between
. This provides a very straightforward method for generating all the polynomials of a given degree, namely by decoding the consecutive integers between ![]() and
and ![]() . For example, here are the third-degree polynomials.
. For example, here are the third-degree polynomials.
![]()
![]()
We note that a polynomial has a constant term if and only if it has an odd ![]() -number. Therefore, to compute primitive polynomials we need consider only those with an odd
-number. Therefore, to compute primitive polynomials we need consider only those with an odd ![]() -number.
-number.
![]()
![]()
The function ![]() generates the polynomials of degree
generates the polynomials of degree ![]() . By default, PolynomialMod2 gives only polynomials with a constant term, which are candidates for being primitive.
. By default, PolynomialMod2 gives only polynomials with a constant term, which are candidates for being primitive.
![]()
![]()
Setting the option WithConstantTerm to False generates all polynomials of the specified degree, including those with no constant term.
![]()
![]()
Irreducible Polynomials
Suppose we attempt to factor the third-degree polynomials with constant term.
![]()

We observe that the first and last polynomials can be factored, while the other two are irreducible. Now examine the heads of the expressions after attempted factorization.
![]()
![]()
The irreducible polynomials have a head of Plus, while the other two have heads of Times or Power. We can use this to identify irreducible polynomials.
![]()
Here are the irreducible third-degree polynomials.
![]()
![]()
Primitive Polynomials
If ![]() is prime, all the irreducible polynomials of degree
is prime, all the irreducible polynomials of degree ![]() are primitive. If not, we must test each of the prime factors of
are primitive. If not, we must test each of the prime factors of ![]() . For example,
. For example, ![]() is not prime. Here are the irreducible polynomials of degree four.
is not prime. Here are the irreducible polynomials of degree four.
![]()
![]()
For each prime factor ![]() of
of ![]() , we have to test whether the polynomial divides
, we have to test whether the polynomial divides ![]() . For
. For ![]() and
and ![]() , the prime factors are 3 and 5, and their cofactors are 5 and 3, respectively. That is, we need to check whether each polynomial divides
, the prime factors are 3 and 5, and their cofactors are 5 and 3, respectively. That is, we need to check whether each polynomial divides ![]() or
or ![]() . Clearly, a fourth-degree polynomial cannot divide
. Clearly, a fourth-degree polynomial cannot divide ![]() . Therefore, we need only check those cofactors less than
. Therefore, we need only check those cofactors less than ![]() . That is, we check whether the irreducible polynomials of degree 4 divide
. That is, we check whether the irreducible polynomials of degree 4 divide ![]() .
.
![]()
![]()
This reveals that the third irreducible polynomial divides ![]() . We conclude that the first and second polynomials are primitive, while the third is not.
. We conclude that the first and second polynomials are primitive, while the third is not.
All fifth-degree irreducible polynomials are primitive, since ![]() is prime. Considering the sixth-degree polynomials, the prime factors of
is prime. Considering the sixth-degree polynomials, the prime factors of ![]() are 3 and 7, and their cofactors are 21 and 9. Consequently, we need to consider the divisibility of the polynomials
are 3 and 7, and their cofactors are 21 and 9. Consequently, we need to consider the divisibility of the polynomials ![]() and
and ![]() .
.
![]()
![]()
![]()
![]()
![]()
![]()
We observe that the third and last polynomial divide ![]() , while the second polynomial divides
, while the second polynomial divides ![]() . The remaining six polynomials are primitive. We summarize this test in the function PrimitiveQ.
. The remaining six polynomials are primitive. We summarize this test in the function PrimitiveQ.
![]()
![]()
The following function generates the primitive polynomials of degree ![]() .
.
![]()
Here are ![]() -numbers of the 52 primitive polynomials up to degree eight.
-numbers of the 52 primitive polynomials up to degree eight.
![]()

The number ![]() of primitive polynomials of degree
of primitive polynomials of degree ![]() can be easily computed from Euler’s totient function
can be easily computed from Euler’s totient function ![]() . Specifically,
. Specifically,
![]()
There are some published sources for primitive polynomials. Numerical Recipes [3] lists all 160 primitive polynomials of degree 10 or less (but note that they use a different encoding). Joe and Kuo [4] provide a list of the 1111 primitive polynomials through degree 13, which they have recently extended to degree 18 [5]. The CD accompanying Jäckel [6] lists all primitive polynomials up to degree 27, a mammoth eight million primitive polynomials.
Implementation
We now give details of the Mathematica implementation of these components.
Direction Numbers
Recall that direction numbers are computed by the recursive sequence (3)
![]()
where ![]() are the coefficients of a degree
are the coefficients of a degree ![]() primitive polynomial
primitive polynomial ![]() ). Each recursion of order
). Each recursion of order ![]() requires
requires ![]() initial values, which are arbitrary odd integers less than
initial values, which are arbitrary odd integers less than ![]() , respectively. To implement this, we extract the binary digits from the
, respectively. To implement this, we extract the binary digits from the ![]() -number of the specified polynomial, use them to define an appropriate recursive function, initialize the function with the vector
-number of the specified polynomial, use them to define an appropriate recursive function, initialize the function with the vector ![]() of initial values, and then map this function over the integers
of initial values, and then map this function over the integers ![]() . The resulting function is called DirectionNumbers.
. The resulting function is called DirectionNumbers.
![]()
![]()
Here are the first six direction numbers for the third primitive polynomial ![]() with initial values
with initial values ![]() .
.
![]()
![]()
Note that DirectionNumbers returns the (integer) numerators of the direction number sequence, which is the form in which they will be used for generating the Sobol sequence. If no direction numbers are specified, the function assumes all initial values are one (unit initialization).
Recursive Sobol Sequence
It is most efficient to compute all ![]() dimensions of a Sobol sequence in parallel, which is especially convenient in Mathematica. To illustrate, we take the primitive polynomials and initial values listed in Numerical Recipes, which are sufficient to generate a six-dimensional sequence.
dimensions of a Sobol sequence in parallel, which is especially convenient in Mathematica. To illustrate, we take the primitive polynomials and initial values listed in Numerical Recipes, which are sufficient to generate a six-dimensional sequence.

To generate 10 points requires ![]() sets of direction numbers, each set containing direction numbers for six dimensions.
sets of direction numbers, each set containing direction numbers for six dimensions.
![]()
![]()
To enable integer computation, it is convenient to scale the first set of direction numbers by ![]() , the second by
, the second by ![]() , and so on.
, and so on.
![]()
![]()
The sequence can then be computed efficiently using FoldList to implement (2) across all dimensions in parallel, then converted to fractions by multiplying each result by ![]() . Here are the first 10 points of the six-dimensional Sobol sequence using the initial values listed in Numerical Recipes.
. Here are the first 10 points of the six-dimensional Sobol sequence using the initial values listed in Numerical Recipes.
![]()

![]() generates a Sobol sequence of
generates a Sobol sequence of ![]() points of dimension
points of dimension ![]() . We give the arguments
. We give the arguments ![]() as a list to conform with the pseudorandom generator RandomReal, and also to suggest that the result is an
as a list to conform with the pseudorandom generator RandomReal, and also to suggest that the result is an ![]() matrix of real numbers.
matrix of real numbers.
We now describe a number of useful variants of the basic function.
Nonrecursive Sobol Sequence
The recursive construction of the Sobol sequence (2) was proposed by Antonov and Saleev [7]. The original construction of Sobol is
| (4) |
where ![]() are the binary digits of
are the binary digits of ![]() , that is
, that is ![]() . The recursive definition (2) is obtained from (4) using a Gray code encoding of
. The recursive definition (2) is obtained from (4) using a Gray code encoding of ![]() . This alters the order of the sequence without changing the asymptotic discrepancy. The original definition is useful for constructing single elements of the sequence.
. This alters the order of the sequence without changing the asymptotic discrepancy. The original definition is useful for constructing single elements of the sequence.
![]() gives the
gives the ![]() element in the (recursive) Sobol sequence.
element in the (recursive) Sobol sequence. ![]() gives the
gives the ![]() element in the original Sobol sequence. For example, here is the
element in the original Sobol sequence. For example, here is the ![]() element in the recursive sequence we computed in the previous subsection.
element in the recursive sequence we computed in the previous subsection.
![]()
![]()
This is the ![]() element in the sequence constructed using (4).
element in the sequence constructed using (4).
![]()
![]()
Equation (4) is useful for initiating the sequence at an arbitrary starting point.
Initial Offset
Note the repetition of coordinates in the initial points of the sequence. For example, in the first 10 points of a three-dimensional sequence, many of the coordinates appear three times.
![]()

To avoid this repetition, many authors recommend discarding the first ![]() points in a Sobol sequence, although the choice of
points in a Sobol sequence, although the choice of ![]() is arbitrary. To this end, we modify the definition to allow setting an initial offset as an option. Setting this option
is arbitrary. To this end, we modify the definition to allow setting an initial offset as an option. Setting this option ![]() will use (4) to generate the first point of the sequence and then use (2) to generate the remaining points of the sequence.
will use (4) to generate the first point of the sequence and then use (2) to generate the remaining points of the sequence.
Strictly speaking, the Sobol sequence begins with the point ![]() , although most implementations exclude this point. A sequence beginning with zero can be obtained by setting the
, although most implementations exclude this point. A sequence beginning with zero can be obtained by setting the ![]() .
.
![]()
![]()
The default value of Offset is 1, generating a sequence beginning with ![]() . That is, Offset specifies the ordinal number of the first element in the sequence.
. That is, Offset specifies the ordinal number of the first element in the sequence.
Specifying the Polynomials and Initial Values
We show below that selection of the initial values is important in determining the quality of the Sobol sequence. We next allow for the initial values to be specified as an option. This is useful for selecting particular dimensions, such as portraying 2D projections. Initial values are specified as a list, each element of which is a polynomial ![]() -number followed by a list of initial values equal in number to the degree of the polynomial.
-number followed by a list of initial values equal in number to the degree of the polynomial.
The following is the two-dimensional sequence extracted from the third and fourth coordinates of the Numerical Recipes implementation.
![]()
![]()
The alternative initial values proposed by Joe and Kuo [5] give a different sequence.
![]()
![]()
Specifying the Polynomials
For some purposes, it will be useful to select only the primitive polynomials and have the initial values supplied by the default value of the InitialValues option. The following input gives the third and fourth coordinates of the Numerical Recipes sequence.
![]()
![]()
This gives a two-dimensional sequence based on the same polynomials, but with different starting values.
![]()
![]()
Unit Initialization
Recall that ![]() -order recursion for building direction numbers requires
-order recursion for building direction numbers requires ![]() initial values that are odd integers less than
initial values that are odd integers less than ![]() . The simplest valid choice for the initial values is to set them all equal to one, which we will call unit initialization. We add this as an option. We will demonstrate in the next section that unit initialization does not produce sequences with the lowest discrepancy.
. The simplest valid choice for the initial values is to set them all equal to one, which we will call unit initialization. We add this as an option. We will demonstrate in the next section that unit initialization does not produce sequences with the lowest discrepancy.
![]()
![]()
Summary
![]() generates a Sobol sequence of
generates a Sobol sequence of ![]() points of dimension
points of dimension ![]() , while
, while ![]() gives the
gives the ![]() element in the same sequence. The function Sobol has the following options, which are listed with their default values:
element in the same sequence. The function Sobol has the following options, which are listed with their default values:

The initial values listed in Numerical Recipes [3] are only sufficient to generate a sequence of six dimensions. Consequently, we adopt the initial values provided by Joe and Kuo [5] as the default option for generating Sobol sequences.
Joe and Kuo provide optimized initial values sufficient for 7800 dimensions on their website at web.maths.unsw.edu.au/~fkuo/sobol/index.html. For economy, we have incorporated only the first 100 values into this accompanying package.
![]()
Evaluation
There are at least three ways in which the performance of low-discrepancy sequences can be evaluated:
- viewing two-dimensional projections
- measuring discrepancy
- evaluating performance in application
We illustrate each in turn.
Projections
A graphic way to explore the discrepancy of pseudorandom and quasirandom sequences is to plot two-dimensional projections. The following graph shows a striking example of the failure of a Sobol sequence to approximate a uniform distribution in particular dimensions. The graph on the left shows the clustering of the first 4096 points in the sequence. The graph on the right shows that the distribution of the next 4096 points exactly complements the distribution of the first 4096 points.

This particular example, taken from Joe and Kuo [5], uses the initial values given by Bratley and Fox [8] in their well-known implementation. Below, we depict two other examples drawn from [5].

These examples underline the importance of the choice of initial values. Joe and Kuo [5] select the initial values specifically to improve these two-dimensional projections. We restore these as the default.
![]()
Measuring Discrepancy
Discrepancy is a measure of the difference between the actual distribution of points and a uniform distribution in which the number of points in any set ![]() is proportional to its size. Specifically, let
is proportional to its size. Specifically, let ![]() be a collection of subsets of the hypercube
be a collection of subsets of the hypercube ![]() . The discrepancy of the sequence
. The discrepancy of the sequence ![]() relative to
relative to ![]() is
is
| (5) |
where ![]() denotes the number of points in
denotes the number of points in ![]() and
and ![]() is the measure of
is the measure of ![]() . Different collections
. Different collections ![]() of sets give rise to different measures. Taking
of sets give rise to different measures. Taking ![]() to be the collection of all rectangles
to be the collection of all rectangles ![]() in
in ![]() gives the ordinary discrepancy; taking
gives the ordinary discrepancy; taking ![]() to be the collection of all rectangles
to be the collection of all rectangles ![]() in
in ![]() gives the star discrepancy. The
gives the star discrepancy. The ![]() norm in (5) is useful in theoretical evaluation, but impractical for measuring the discrepancy of specific sequences. If we substitute the Euclidean
norm in (5) is useful in theoretical evaluation, but impractical for measuring the discrepancy of specific sequences. If we substitute the Euclidean ![]() norm, it is possible to derive explicit formulas for both ordinary
norm, it is possible to derive explicit formulas for both ordinary ![]() and the star
and the star ![]() discrepancy of a given sequence [9]:
discrepancy of a given sequence [9]:
 |
(6) |
These calculations are implemented in the functions DiscrepancySqd and StarDiscrepancySqd.
![]()

We can also calculate the expected value of these quantities for a genuinely random sequence [9]:
| (7) |
These formulas are implemented in the corresponding functions EDiscrepancySqd and EStarDiscrepancySqd.
To illustrate, the following computation shows the discrepancy of a three-dimensional Sobol sequence relative to that expected of a purely random sequence. Remember that discrepancy measures the degree of nonuniformity in the distribution of the sequence. By this measure, we observe that the quasirandom sequence is three to six times more uniform than what would be expected of a purely random sequence. However, the advantage of the quasirandom sequence erodes as the number of dimensions is increased. (This input takes a long time to evaluate.)
![]()
Since computing discrepancy using (6) requires combining every pair of random vectors ![]() ,
, ![]() , the time required increases linearly with the dimension
, the time required increases linearly with the dimension ![]() but quadratically with
but quadratically with ![]() . Computation of (6) in Mathematica will run significantly faster if we ensure that floating-point rather than exact arithmetic is used, which is why we apply N to the arguments of DiscrepancySqd and StarDiscrepancySqd in the previous calculation.
. Computation of (6) in Mathematica will run significantly faster if we ensure that floating-point rather than exact arithmetic is used, which is why we apply N to the arguments of DiscrepancySqd and StarDiscrepancySqd in the previous calculation.
Our implementation of DiscrepancySqd and StarDiscrepancySqd is a straightforward translation of the expressions in (6). These functions can be written more efficiently and then compiled to improve their execution speed by an order of magnitude. (I am grateful to the referee for demonstrating this.) However, the compiled functions are still too slow to be practical for large values of ![]() . Consequently, the following graphs were produced using discrepancy functions implemented in C++ and accessed through MathLink. The source code and the MathLink executable together with instructions for its use are available from the author on request.
. Consequently, the following graphs were produced using discrepancy functions implemented in C++ and accessed through MathLink. The source code and the MathLink executable together with instructions for its use are available from the author on request.
The following graph compares the discrepancy of Sobol sequences of varying length relative to the expected discrepancy of a purely random sequence, using the two measures of discrepancy. We observe that the two measures are broadly consistent, both indicating that the relative advantage of the quasirandom sequence dissipates with increasing dimension. (The horizontal axis is scaled in binary thousands, that is 1024.) Star discrepancy has generally been favored as a measure because it can be used to bound integration error (see [9, 10]).

The following graph compares the discrepancy of pseudorandom and quasirandom sequences relative to the expected discrepancy of a purely random sequence as we vary the dimension ![]() . This confirms the conventional wisdom that low-discrepancy sequences (blue) outperform pseudorandom sequences (red) for low dimensions, but that their advantage is eroded as the dimension is increased, with the crossover around
. This confirms the conventional wisdom that low-discrepancy sequences (blue) outperform pseudorandom sequences (red) for low dimensions, but that their advantage is eroded as the dimension is increased, with the crossover around ![]() ([11, p. 75]). The measured discrepancy of the pseudorandom sequence (red) hovers around its expected value, so its relative discrepancy is close to the horizontal axis located at 1. The dashed curve shows the discrepancy of a Sobol sequence constructed using unit initialization.
([11, p. 75]). The measured discrepancy of the pseudorandom sequence (red) hovers around its expected value, so its relative discrepancy is close to the horizontal axis located at 1. The dashed curve shows the discrepancy of a Sobol sequence constructed using unit initialization.

The next graph makes the same comparison using the star discrepancy. Under this measure, the quasirandom sequence (blue) appears to remain competitive with the pseudorandom sequence (red) for higher dimensions. We conclude that the evaluation of the relative performance of quasirandom versus pseudorandom sequences at higher dimensions depends upon the measure of discrepancy used. This graph emphasizes the importance of initial values. The dashed curve shows the relative star discrepancy of a Sobol sequence constructed with unit initialization deteriorates dramatically at higher dimensions.

Jäckel [6] includes a more extensive range of comparisons, covering a greater variety of dimensions and other low-discrepancy sequences.
Performance in Practice
The following graph compares three methods of estimating ![]() by simulation. The blue line shows the estimate of
by simulation. The blue line shows the estimate of ![]() from a low-discrepancy sequence of varying sizes, bracketed by the estimates from a rectangular grid (green) and a pseudorandom sequence (red) of identical size. We observe that the low-discrepancy sequence generally provides a more accurate estimate than the rectangular grid, and a significantly better estimate than the pseudorandom sequence. (This input takes a long time to evaluate.)
from a low-discrepancy sequence of varying sizes, bracketed by the estimates from a rectangular grid (green) and a pseudorandom sequence (red) of identical size. We observe that the low-discrepancy sequence generally provides a more accurate estimate than the rectangular grid, and a significantly better estimate than the pseudorandom sequence. (This input takes a long time to evaluate.)


The estimation of ![]() is a one-dimensional problem, where the advantage of low-discrepancy sequences is most pronounced. The world of finance provides a host of multidimensional problems of immense practical importance. A derivative is a financial instrument whose value depends upon the evolution of the price of some underlying asset. Estimating its current value by simulation requires calculating its hypothetical value for each realization, averaging and discounting back to the current time. In the case of a vanilla European option, the payoff of the derivative depends only on the price of the underlying asset at the maturity of the option. For an Asian option, in contrast, the payoff of the derivative depends upon the average price over the term of the option. In effect, estimating the value of an Asian option by simulation amounts to computing a multidimensional integral, with the number of dimensions equal to the number of prices included in the average.
is a one-dimensional problem, where the advantage of low-discrepancy sequences is most pronounced. The world of finance provides a host of multidimensional problems of immense practical importance. A derivative is a financial instrument whose value depends upon the evolution of the price of some underlying asset. Estimating its current value by simulation requires calculating its hypothetical value for each realization, averaging and discounting back to the current time. In the case of a vanilla European option, the payoff of the derivative depends only on the price of the underlying asset at the maturity of the option. For an Asian option, in contrast, the payoff of the derivative depends upon the average price over the term of the option. In effect, estimating the value of an Asian option by simulation amounts to computing a multidimensional integral, with the number of dimensions equal to the number of prices included in the average.
Specifically, the payoff of an Asian option depends upon the average price ![]() of the underlying asset during the life of the option. For example, the payoff at maturity of an average price call option is
of the underlying asset during the life of the option. For example, the payoff at maturity of an average price call option is ![]() , where
, where ![]() is the strike price. There are two ways of calculating the average
is the strike price. There are two ways of calculating the average ![]() —arithmetic or geometric:
—arithmetic or geometric:
![]()
Arithmetic averaging is almost universal in practice. However, geometric averaging is more tractable; indeed, the value of a geometric Asian option is given by an analytical formula. One of the most successful techniques for valuing arithmetic Asian options is simulation, using the known value of a corresponding geometric average option to reduce the simulation error. Consequently, geometric Asian options provide a useful financial test bed for evaluating different simulation methods.
The following graph compares pseudorandom and quasirandom simulations of a one-year geometric average Asian option for varying sample sizes. In the left-hand graphic, the number of dimensions ![]() , corresponding to monthly averaging. In the right-hand graphic,
, corresponding to monthly averaging. In the right-hand graphic, ![]() , simulating weekly averaging. The axes are drawn at the true value. The law of large numbers ensures that simulated value will converge to the true value eventually. However, as we observe in this diagram, this convergence may be very slow. In both cases, the quasirandom simulation (blue) converges faster than the pseudorandom simulation (red), though the advantage erodes as the number of dimensions increases. We find that the superiority of Sobol sequences in practical applications extends to higher dimensions than might be suggested by considering discrepancy alone. In this example, quasirandom simulation based on a Sobol sequence shows markedly better convergence than pseudorandom simulation, even in a problem of 52 dimensions. Galanti and Jung [11] report extensive comparisons of pseudorandom and quasirandom simulation in financial applications. They observe that quasirandom simulation remains competitive with pseudorandom simulation up to at least 250 dimensions, which would correspond to daily averaging in a one-year option. (This input takes a long time to evaluate.)
, simulating weekly averaging. The axes are drawn at the true value. The law of large numbers ensures that simulated value will converge to the true value eventually. However, as we observe in this diagram, this convergence may be very slow. In both cases, the quasirandom simulation (blue) converges faster than the pseudorandom simulation (red), though the advantage erodes as the number of dimensions increases. We find that the superiority of Sobol sequences in practical applications extends to higher dimensions than might be suggested by considering discrepancy alone. In this example, quasirandom simulation based on a Sobol sequence shows markedly better convergence than pseudorandom simulation, even in a problem of 52 dimensions. Galanti and Jung [11] report extensive comparisons of pseudorandom and quasirandom simulation in financial applications. They observe that quasirandom simulation remains competitive with pseudorandom simulation up to at least 250 dimensions, which would correspond to daily averaging in a one-year option. (This input takes a long time to evaluate.)


Selection of Initial Values
The preceding section emphasized that initial values must be selected cautiously. Sobol proposed property A to guide the selection of initial values. To understand property A, consider the following diagram, which shows the unit square divided into four subsquares. The blue points are four successive points in a Sobol sequence (starting at ![]() ), and the red points are the next four points. In the left-hand graphic, we observe that the blue points belong to different subsquares, as do the red points. This conforms with property A. This is not the case in the graphic on the right, which is constructed from analogous points in a sequence with unit initialization. The second sequence does not satisfy property A.
), and the red points are the next four points. In the left-hand graphic, we observe that the blue points belong to different subsquares, as do the red points. This conforms with property A. This is not the case in the graphic on the right, which is constructed from analogous points in a sequence with unit initialization. The second sequence does not satisfy property A.

Generalizing to ![]() dimensions, divide the hypercube
dimensions, divide the hypercube ![]() into
into ![]() equally sized subcubes and partition a sequence of points in
equally sized subcubes and partition a sequence of points in ![]() into blocks of
into blocks of ![]() points. The sequence satisfies property A if each of the points in any block belongs to a different subcube. An analogous property A’ applies when each dimension is divided into quarters. These properties can be verified by evaluating determinants.
points. The sequence satisfies property A if each of the points in any block belongs to a different subcube. An analogous property A’ applies when each dimension is divided into quarters. These properties can be verified by evaluating determinants.
Bratley and Fox [8] give initial values for 40 dimensions that are claimed to satisfy property A; Joe and Kuo [4] extend this to 1111 dimensions. However, property A is of limited value in high dimensions, since it is computationally infeasible to use sufficient points to reap an advantage. To benefit from property A in a problem with 250 dimensions would require using ![]() points of the sequence, which is larger than the estimated number of particles in the known universe!
points of the sequence, which is larger than the estimated number of particles in the known universe!
Joe and Kuo [5] provide a set of initial values designed to minimize bad projections between pairs of variables. They provide initial values for all polynomials up to degree 18 (21200 dimensions), and claim that they satisfy property A up to 1111 dimensions. The implementation of Lemieux, Cieslak, and Luttmer [12] gives values for 360 dimensions selected on the basis of an optimization. The British-Russian Offshore Development Agency (BRODA)—with which Sobol is affiliated—sells proprietary software to generate sequences with up to 1024 dimensions. Alternatively, Jäckel [6] advocates a randomization procedure to select initial values in higher dimensions.
Starting with Version 6, Mathematica includes an option for producing Sobol and Niederreiter sequences as part of its random number generation facility. This comes courtesy of the Intel MKL libraries, which are available for Microsoft Windows (32-bit, 64-bit), Linux x86 (32-bit, 64-bit), and Linux Itanium systems. Specifics of the implementation, such as choice of initial values, are not documented. Evaluation of this implementation in terms of discrepancy, projections, and performance in application remains for future work.
Acknowledgments
I gratefully acknowledge the very helpful comments of two anonymous referees.
References
| [1] | E. Siniksaran, “Throwing Buffon’s Needle with Mathematica,” The Mathematica Journal, 11(1), 2008 pp. 71-90. www.mathematica-journal.com/2009/01/throwing-buffons-needle-with-mathematica. |
| [2] | D. Knuth, The Art of Computer Programming, Volume 2: Seminumerical Algorithms, 2nd ed., Reading, MA: Addison-Wesley, 1981. |
| [3] | W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery, Numerical Recipes in C: The Art of Scientific Computing, 2nd ed., New York: Cambridge University Press, 1992. |
| [4] | S. Joe and F. Y. Kuo, “Remark on Algorithm 659: Implementing Sobol’s Quasirandom Sequence Generator,” ACM Transactions on Mathematical Software, 29(1), 2003 pp. 49-57. doi:10.1145/641876.641879. |
| [5] | S. Joe and F. Y. Kuo, “Constructing Sobol Sequences with Better Two-Dimensional Projections,” SIAM Journal on Scientific Computing, 30(5), 2007 pp. 2635-2654. doi:10.1137/070709359. |
| [6] | P. Jäckel, Monte Carlo Methods in Finance, Chichester, England: Wiley, 2002. |
| [7] | I. A. Antonov and V. M. Saleev, “An Economic Method of Computing |
| [8] | P. Bratley and B. L. Fox, “Algorithm 659: Implementing Sobol’s Quasirandom Sequence Generator,” ACM Transactions on Mathematical Software 14(1), 1988 pp. 88-100. doi:10.1145/42288.214372. |
| [9] | W. J. Morokoff and R. E. Caflisch, “Quasi-Random Sequences and Their Discrepancies,” SIAM Journal on Scientific Computing 15(6), 1994 pp. 1251-1279. doi:10.1137/0915077. |
| [10] | P. Glasserman, Monte Carlo Methods in Financial Engineering, New York: Springer, 2003. |
| [11] | S. Galanti and A. Jung, “Low-Discrepancy Sequences: Monte Carlo Simulation of Option Prices,” Journal of Derivatives 5(1), 1997 pp. 63-83. doi:10.3905/jod.1997.407985. |
| [12] | C. Lemieux, M. Cieslak, and K. Luttmer, RandQMC User’s Guide: A Package for Randomized Quasi-Monte Carlo Methods in C, Technical report 2002-712-15, Department of Computer Science, University of Calgary, 2002. hdl.handle.net/1880/46569. |
| M. Carter, “A Toolbox for Quasirandom Simulation,” The Mathematica Journal, 2011. dx.doi.org/doi:10.3888/tmj.13-21. | |
About the Author
Michael Carter (Ph.D. in economics, Stanford University) has taught in Asia, Europe, and the U.S. His research interests include computational finance, industrial and mathematical economics, and game theory. He has previously published articles in The Mathematica Journal on game theory and optimization.
Michael Carter
Adjunct Professor of Finance
Indian Institute of Management, Ahmedabad
carter@iimahd.ernet.in or carter@uni-hohenheim.de