An enumeration of strings is developed, in which all strings of finite length of symbols from any alphabet appear, with no upper bounds for string length or alphabet size. A bijective indexing function and its inverse are found for the string enumeration, allowing iteration through the set of all strings, as well as identification of arbitrary strings by the associated index. The method is then extended to sequences of strings and to sequential substitution system (SSS) rulesets, providing a well-defined, relatively dense enumeration of all possible valid SSS rulesets for strings of arbitrary length and any number of symbols used in rulesets of any length, although in this case the indexing function is not one-to-one.
Introduction
Enumerations are useful, both theoretically and practically. The existence of a set enumeration guarantees that the set is at most countably infinite. For example, an enumeration of the rationals proved that there are the same number of fractions as integers, while a proof that no enumeration of the reals exists showed that the real numbers are uncountable. More usefully, an enumeration assigns an index to every member of the set under consideration, giving a practical means to consider every case. This makes enumeration a powerful part of the methodology found in NKS [1]. Given a function Enumeration that returns the elements of a set in specified order, the following command finds the index of the first element that passes TestFunction. (The next cell does not evaluate.)
![]()
Sequential substitution systems are defined by sets of rules (here called “rulesets”), each consisting of a target string and a replacement string. Given some initial state (which may also be represented as a string), these rules are applied and the system evolves. But without a well-defined enumeration of strings and rulesets, any treatment of sequential substitution systems will be haphazard and may miss important features. In this article enumeration systems are presented for all strings, for all lists of strings, and for all sequential substitution system rulesets. These enumerations can be used or modified for other applications based on rulesets and initial state strings (for example, nonsequential substitution systems, multiway systems, etc.).
Toward an Exhaustive List of Strings
Strings of Fixed Length and Fixed Number of Symbols
To generate a list of all possible strings of length three and made up of the characters A and B, the obvious method would be to think of a binary odometer having three positions, each able to display an A or a B—or a 0 or a 1. This is the normal increasing order of the first ![]() binary numbers.
binary numbers.
![]()
![]()
![]()
![]()
We can identify each two-symbol length-three string with the corresponding numbers in the set ![]() , providing an index into the sequence of strings, which appear in alphabetical order. But suppose we want to include all two-symbol strings, no matter what length? One possible ordering is the following.
, providing an index into the sequence of strings, which appear in alphabetical order. But suppose we want to include all two-symbol strings, no matter what length? One possible ordering is the following.
![]()
The pattern is: list all length-zero strings, then all length-one strings, then all length-two strings, then all length-three strings, etc. For a given length, go through the strings as you would odometer readings, changing the rightmost character most frequently, and others when the character to the right “rolls over.” Notice that the ordering is not alphabetic; if it were it would start with ![]() and would never get to any strings that include B. But the order is well defined, with strings sorted first by length, then alphabetically within each string length group.
and would never get to any strings that include B. But the order is well defined, with strings sorted first by length, then alphabetically within each string length group.
This method can be applied for any specified alphabet size. Below are functions to work with arbitrary-length strings with alphabet size ![]() , here limited to 26 for the convenience of using the English alphabet, although the maximum for the function IntegerString is 36. (See [2] for an example of how to construct basically the same enumeration with no size limitation on the specified alphabet size by avoiding the use of an actual alphabet, listing characters by number only.)
, here limited to 26 for the convenience of using the English alphabet, although the maximum for the function IntegerString is 36. (See [2] for an example of how to construct basically the same enumeration with no size limitation on the specified alphabet size by avoiding the use of an actual alphabet, listing characters by number only.)


The single-symbol case is treated separately, simply counting or combining the appropriate number of characters. The more general formulas use as the string index the sum of the number of possible strings of length shorter than len and the base-![]() representation of the desired length string, where
representation of the desired length string, where ![]() is the alphabet size. Since for
is the alphabet size. Since for ![]() symbols there are
symbols there are ![]() strings of length 1,
strings of length 1, ![]() strings of length 2, etc., the number of strings of length less than len is as follows.
strings of length 2, etc., the number of strings of length less than len is as follows.
![]()
![]()
![]() generates the string associated with the index number
generates the string associated with the index number ![]() in the listing of
in the listing of ![]() -symbol strings, starting with 0. For
-symbol strings, starting with 0. For ![]() , string length less than five, the indices can run from 0 to
, string length less than five, the indices can run from 0 to ![]() .
.
![]()
![]()
![]()
![]()
These are all strings of length less than five on an alphabet of two symbols. We use ![]() to return the index of each string.
to return the index of each string.
![]()
![]()
![]() and
and ![]() are constructed to act as inverse functions, converting a string
are constructed to act as inverse functions, converting a string ![]() into an integer
into an integer ![]() and vice versa, subject to the present limitations that
and vice versa, subject to the present limitations that ![]() and
and ![]() be a string of uppercase characters taken from the first
be a string of uppercase characters taken from the first ![]() letters of the English alphabet.
letters of the English alphabet. ![]() produces a unique string
produces a unique string ![]() for each non-negative integer
for each non-negative integer ![]() , and
, and ![]() reconstructs the index from the string. (Note that there is no limitation on string length or the index.)
reconstructs the index from the string. (Note that there is no limitation on string length or the index.)
Choose any string and an allowed (sufficiently large) base ![]() .
.
![]()
![]()
The inverse function retrieves the string.
![]()
![]()
Starting from an index is easier. We can iterate through its values, for example by moving a slider.


Note that UnrankStringInBase could even be used in an infinite loop, iterating through all strings for a given set of symbols, listing shorter strings before longer ones. In the following loop, rather than using While[True, ], we stop when the string length exceeds three.


There are several nice things about these functions. UnrankStringInBase enumerates the ![]() -symbol strings in the specified order (sorted with shorter strings first, alphabetically within each string length), giving a “standard order” for listing these strings without omissions. But notice that RankStringInBase and UnrankStringInBase do not generate this (infinite!) list and look for a match or pick out an element, rather they build the string from the index or deduce the index from the string, respectively.
-symbol strings in the specified order (sorted with shorter strings first, alphabetically within each string length), giving a “standard order” for listing these strings without omissions. But notice that RankStringInBase and UnrankStringInBase do not generate this (infinite!) list and look for a match or pick out an element, rather they build the string from the index or deduce the index from the string, respectively.
Duplication of Effort
Of course, the particular enumeration order chosen motivates the creation of the rank and unrank functions. The above method includes all possible strings written using an alphabet of ![]() symbols, and does so in an explainable order. But although by construction it allows all string lengths, whenever the alphabet size is increased all the previous work must be redone.
symbols, and does so in an explainable order. But although by construction it allows all string lengths, whenever the alphabet size is increased all the previous work must be redone.
Is there a way to list all strings, allowing both string length and alphabet size to grow without upper bound? (For the sake of argument let us assume that the symbols themselves can be written down in some order, perhaps Unicode order followed by the order in which new symbols are invented.) What is needed is some way to add to the list without rearranging or repeating previously listed entries. For inspiration we turn to a similar situation, the enumeration of the rational numbers.
Rational Examples
Cantor’s Diagonalization
There are ways to create an ordered list of things that grow infinitely in two different “directions.” One is Georg Cantor’s famous diagonal ordering of the rational numbers (see Figure 1, below).

Figure 1. Cantor’s diagonal ordering of the rationals: coloration added to highlight diagonal rows.
Both the numerator and the denominator of the fraction are taken from an infinite (but countable) set, and rather than trying to treat one infinity first, as in ![]() , this method allows growth in both directions to continue indefinitely, following a defined pattern while clearly including all possible combinations. (See [3] for an alternative route through the array.) Of course, one drawback of this method as applied to fractions is that equivalent fractions get counted multiple times. For example
, this method allows growth in both directions to continue indefinitely, following a defined pattern while clearly including all possible combinations. (See [3] for an alternative route through the array.) Of course, one drawback of this method as applied to fractions is that equivalent fractions get counted multiple times. For example ![]() , etc. But the mathematical literature contains many examples of nonrepetitive ways of ordering the rationals (e.g., [4, 5, 6, 7, 8]).
, etc. But the mathematical literature contains many examples of nonrepetitive ways of ordering the rationals (e.g., [4, 5, 6, 7, 8]).
None of the nonrepetitive sequences has the simple clarity of the diagonal arrangement. Is it so bad to have duplicates and then be forced to ignore or drop them later? This is an important question that will return in various situations. Although a little inelegant, the existence of duplicates hurts nothing essential, so we will consider nonrepetition a desirable but not necessary feature.
What is essential then?
- The list should be unambiguous: it can be generated to any desired number of elements, and the order can be unambiguously described. Here the fractions are listed in increasing order first by the sum of numerator and denominator (as colored in Figure 1), next by numerator.
- A successor algorithm should exist: from a given fraction
 , can the next fraction in the list be found? Yes, if
, can the next fraction in the list be found? Yes, if  , the next fraction is
, the next fraction is  ; if
; if  , it is
, it is  . This means that we do not need to generate the whole list at once; we can proceed one step at a time, perhaps testing or making some use of the fractions as they are generated. A small modification to the successor algorithm lets us easily bypass duplicates: if the successor found is not a fraction reduced to lowest terms, advance to its successor. This can be implemented in this way as two-element lists.
. This means that we do not need to generate the whole list at once; we can proceed one step at a time, perhaps testing or making some use of the fractions as they are generated. A small modification to the successor algorithm lets us easily bypass duplicates: if the successor found is not a fraction reduced to lowest terms, advance to its successor. This can be implemented in this way as two-element lists. - The existence of rank and unrank functions, to convert back and forth between the list and an ordered list of integers. (Given such functions, the definition for
 might be as simple as
might be as simple as  , if no direct method of advancing through the enumeration has been found.) For the diagonal ordering, we must determine which diagonal we want and then which element. The fraction
, if no direct method of advancing through the enumeration has been found.) For the diagonal ordering, we must determine which diagonal we want and then which element. The fraction  appears on the
appears on the  and is element
and is element  on that diagonal. An easy way to do this is to create a function to generate the
on that diagonal. An easy way to do this is to create a function to generate the  triangular number (the total number of entries in the previous diagonals).
triangular number (the total number of entries in the previous diagonals).
![]()
![]()
![]()
![]()
![]()
![]()
Now the ranking function is easy.
![]()
![]()
![]()
Except for unreduced fractions these are in ascending order, as desired. An unranking function will facilitate testing for unreduced fractions.
![]()
![]()
![]()

![]()
![]()
![]()
![]()
Since this method of listing the rationals includes duplicates, the UnrankRational function returns 0 instead of a duplicate. However the nonzero fractions returned are unique and appear in the defined order.
Again, although it would be nice for the mapping or indexing method to be one to one, it is not necessary.
Nonrepetitive Indexing of the Rationals
As mentioned above, there are one to one and onto (bijective) mappings between the set of rationals (either all rationals or the positive rationals) and ![]() , the set of positive integers. One elegant algorithm [4] relies on the fundamental theorem of arithmetic (also known as the unique prime factorization theorem): any integer greater than 1 can be written as a unique product of prime numbers (up to the order of the factors).
, the set of positive integers. One elegant algorithm [4] relies on the fundamental theorem of arithmetic (also known as the unique prime factorization theorem): any integer greater than 1 can be written as a unique product of prime numbers (up to the order of the factors).
![]()
![]()
If the prime numbers are listed in order, the sequence of exponents provides a unique way to characterize each positive integer. For the above example the sequence is ![]() . But the same can be said of all possible numerators and denominators of rational numbers, and furthermore, when a fraction is reduced to lowest terms no prime factor will appear in both the numerator and the denominator, a fact that motivates the following algorithm, in which odd exponents define factors of the numerator and even exponents define factors of the denominator.
. But the same can be said of all possible numerators and denominators of rational numbers, and furthermore, when a fraction is reduced to lowest terms no prime factor will appear in both the numerator and the denominator, a fact that motivates the following algorithm, in which odd exponents define factors of the numerator and even exponents define factors of the denominator.
![]()
![]()
![]()
![]()
![]()
Note that even exponents are halved and then used as the exponents of the same prime factors in the denominator, odd exponents incremented, then halved and similarly used to specify the numerator. (For an extension to all rationals see [9].) Of course this procedure is not unique, the treatment of odd and even exponents could just as well be reversed. A disadvantage of this method of ordering the rationals is the order itself: it preferentially treats integers (and in general, small denominator fractions) before others.
![]()

The ordering function is well defined, one to one, and onto, but for example, 2/5 is far later in the list than 5/2, appearing after the integers 47 and 17, respectively. This may not necessarily be appropriate for some applications.
Another bijective ordering of the rationals, due to Calkin and Wilf [6], is treated here. This ordering can be expressed in terms of the hyperbinary function, which can be recursively defined as follows.
![]()
![]()
![]()
(The additional ![]() in the recursion calls is Mathematica‘s standard method (called memoization) of saving the results of a function call so that it will not need to be recalculated after the first time. Its effect can be seen by executing
in the recursion calls is Mathematica‘s standard method (called memoization) of saving the results of a function call so that it will not need to be recalculated after the first time. Its effect can be seen by executing ![]() .)
.)
![]()
![]()

Now the ordered list of rationals is obtained by forming ratios of adjacent elements of the hyperbinary list.
![]()
![]()
![]()
Besides containing no duplicate or unreduced fractions, this ordering has the property that fractions with a small numerator and denominator tend to appear before those with larger ones. An inverse function can be created using the hyperbinary numbers as a look-up table, but musings in [10] motivate a more direct approach. Consider the numerator ![]() and denominator
and denominator ![]() of the reduced fraction: we begin constructing a sequence of 0s and 1s by recording a 0 if
of the reduced fraction: we begin constructing a sequence of 0s and 1s by recording a 0 if ![]() or a 1 if
or a 1 if ![]() . Then a new fraction is formed by replacing the larger (of the numerator and denominator) by their difference, and repeat. Nice features of this process are:
. Then a new fraction is formed by replacing the larger (of the numerator and denominator) by their difference, and repeat. Nice features of this process are:
- Each fraction so produced is automatically in reduced form.
- Either the numerator or the denominator of each fraction is smaller than that of the preceding one.
- The process will inevitably terminate when
 .
.
Now this sequence of binary digits can be interpreted as a unique integer. To recover the index of the fraction, we use the digit sequence in the reverse of the order in which it was generated, and prepend a 1 to distinguish shorter digit sequences from sequences with initial 0s. (This corresponds to counting the number of possible shorter sequences and adding it to the index—a concept we return to when considering the indexing of the set of all strings.)
![]()
![]()
![]()
![]()
![]()
Another excellent feature of this algorithm is that it lends itself to the creation of a successor function, such as was possible for the simple diagonal method of ordering fractions.
![]()
![]()
![]()
One-to-One and Onto Indexing of All Strings?
First Attempt
How can we do something similar with strings of any length and any alphabet size? Suppose we lay out subsets of strings having ![]() symbols and length
symbols and length ![]() and use the diagonal method to choose which subset to include next in the set of strings of all lengths and all number of symbols.
and use the diagonal method to choose which subset to include next in the set of strings of all lengths and all number of symbols.

In this scenario, ![]() is the subset of all strings of length three using an alphabet of two characters. Each subset is finite (
is the subset of all strings of length three using an alphabet of two characters. Each subset is finite (![]() has
has ![]() elements), and so the diagonal method ensures that we will eventually get to any given subset.
elements), and so the diagonal method ensures that we will eventually get to any given subset.
The situation is not analogous to the diagonal listing of fractions, since ![]() ≠
≠ ![]() , etc. So there are no duplicate subsets to remove.
, etc. So there are no duplicate subsets to remove.


For completeness we also defined ![]() as the set containing only the zero-length string, and will let this be the first element in our overall list of strings of any length and any number of characters. Now the list of strings of any length and number of characters, up to the fourth diagonal, is as follows.
as the set containing only the zero-length string, and will let this be the first element in our overall list of strings of any length and any number of characters. Now the list of strings of any length and number of characters, up to the fourth diagonal, is as follows.
![]()
![]()
We see that there are indeed duplicate strings in our list. In fact, every string list in the array layout is a subset of its neighbor to the right: ![]() . Let us remove the duplicates in the sample above.
. Let us remove the duplicates in the sample above.
![]()
![]()
Rank and Unrank Strings of  Symbols?
Symbols?
We could define rank and unrank functions that simply skipped over these duplicates (as in the simple diagonalization ordering of fractions), but might there not be a way of listing all strings without duplicates? The list above can be thought of, to a first approximation, as a list sorted by weight, where the weight of a string is the sum of the weights of its characters and the weights of the characters increase in alphabetical order in some fashion. Suppose we try ![]() . For convenience we again stop at
. For convenience we again stop at ![]() , but could just as easily continue through all symbols in some agreed upon order.
, but could just as easily continue through all symbols in some agreed upon order.
![]()
![]()
![]()
![]()
The reason the string weights do not appear in nondecreasing order is because the way the list was formed does not follow from this simple weighting scheme. In order to create rank and unrank functions we might figure out some other way to index this list, or we could index the more easily understood list including duplicates, and just identify and then ignore duplicates. But suppose instead we start with a weighting scheme and generate a string from it?
The simple weighting scheme ![]() , together with the definition of the weight of a string as the sum of the weights of its characters, suggests a string enumeration that lists strings in increasing order of weight, all strings of weight
, together with the definition of the weight of a string as the sum of the weights of its characters, suggests a string enumeration that lists strings in increasing order of weight, all strings of weight ![]() appearing before those of weight
appearing before those of weight ![]() , for any non-negative integer
, for any non-negative integer ![]() . For example, the strings with weights 1 to 4 are shown in this table.
. For example, the strings with weights 1 to 4 are shown in this table.

The enumeration could simply be the concatenation of these rows into a single list, with some additional ordering system for arranging the strings within the rows. Clearly any finite string ![]() has some positive integer weight and will therefore appear somewhere in the table. It will also become clear that each row is finite, so
has some positive integer weight and will therefore appear somewhere in the table. It will also become clear that each row is finite, so ![]() will appear in the enumeration at a position dependent on its position within its row (weight group) and the total number of strings of lesser weight. To clarify these statements and provide an algorithm for the enumeration, we turn to the concept of integer compositions.
will appear in the enumeration at a position dependent on its position within its row (weight group) and the total number of strings of lesser weight. To clarify these statements and provide an algorithm for the enumeration, we turn to the concept of integer compositions.
Integer Compositions and Partitions
In number theory, partitions and compositions of a positive integer ![]() are ways of writing
are ways of writing ![]() as a sum of positive integers [11, 12]. Here are the ways of dividing 4 into positive integer parts.
as a sum of positive integers [11, 12]. Here are the ways of dividing 4 into positive integer parts.
![]()
![]()
That is to say, 4 can be written as the sum of positive integers in the following ways.
![]()
![]()
In the case of an integer partition, the order is irrelevant. By contrast, permutations of addends may result in distinct integer compositions.
![]()
![]()
![]()
Surprisingly enough, the number of compositions of ![]() is a simple formula. By inspection we get a first clue.
is a simple formula. By inspection we get a first clue.

![]()
Hypothesis: the number of integer compositions of ![]() is
is ![]() .
.
This result suggests the existence of a natural method of associating binary numbers and integer compositions.
Any integer composition of a positive integer ![]() (assuming nonzero parts) can be thought of as a sequence of 1s, interleaved by either commas or plus signs. Since there are
(assuming nonzero parts) can be thought of as a sequence of 1s, interleaved by either commas or plus signs. Since there are ![]() positions where two choices can be made (that is, whether to insert , or +), the number of possible results is
positions where two choices can be made (that is, whether to insert , or +), the number of possible results is ![]() . For instance, the compositions of 4 shown above can all be represented as follows.
. For instance, the compositions of 4 shown above can all be represented as follows.
![]()
![]()
An obvious ordering of the compositions is to let 0 and 1 represent a plus sign and a comma, respectively, so that each composition can be indexed by a binary number. For example, there are ![]() compositions of 4.
compositions of 4.

The next output shows graphically how the bits of the index are used to determine which integer composition is intended. Each 0 in the binary code is interpreted as the instruction “insert a comma before the next 1 in the composition” or “end this integer, start the next as a 1”; each 1 is an instruction to “insert a plus sign before the next 1” or “increment the last integer in the composition.”
This shows the beginning of the tree of all integer compositions, showing compositions of ![]() on level
on level ![]() .
.
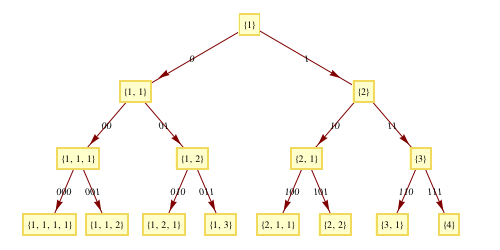
A New String Ordering
This elegant concept immediately gives us an unambiguous order for the set of all strings as well: we need only let ![]() and run through all
and run through all ![]() possibilities for each
possibilities for each ![]() , in all cases letting the integer compositions obtained represent strings using the simple substitutions defined in characterWeights. The following function produces the
, in all cases letting the integer compositions obtained represent strings using the simple substitutions defined in characterWeights. The following function produces the ![]() string of weight
string of weight ![]() by treating the 0s and 1s of the
by treating the 0s and 1s of the ![]() -bit binary representation of
-bit binary representation of ![]() as instructions to either stop or continue incrementing the last digit of the string.
as instructions to either stop or continue incrementing the last digit of the string.
![]()
Here is the same tree as before, but with the integer compositions translated into strings. Note that all strings of weight ![]() appear on level
appear on level ![]() of the tree. Each 0 means “append an A to the string”; each 1 means “increment the final character of the string.”
of the tree. Each 0 means “append an A to the string”; each 1 means “increment the final character of the string.”

Here then are all the strings of weight 4.
![]()
![]()
Notice that StringN is in fact an unrank function for strings of any specified weight, and at the same time it provides a way to generate the list of all such strings. And since each such list is finite, we can join lists of successively greater weighting values to create the universal list of all strings. (Recall the diagonal ordering of fractions first by the sum of numerator and denominator, then by numerator, in which each diagonal was finite.)
![]()

Remember that level ![]() consists of all
consists of all ![]() strings (no matter what length) of weight
strings (no matter what length) of weight ![]() . In order to index this universal string list, we need to know how many strings there are in the levels up to and including
. In order to index this universal string list, we need to know how many strings there are in the levels up to and including ![]() .
.
![]()
![]()
If we include the empty string of length zero, there are ![]() strings of weight less than or equal to
strings of weight less than or equal to ![]() . So given an index
. So given an index ![]() , we first find the largest value
, we first find the largest value ![]() such that
such that ![]() , then pass
, then pass ![]() as the index into the list of strings with weight
as the index into the list of strings with weight ![]() , returning
, returning ![]() . (The next cell does not evaluate.)
. (The next cell does not evaluate.)
![]()
The above definition is included only for clarity. For increased computational speed we replace it by the following functionally equivalent version using BitLength, a function that returns the number of binary digits needed to express an integer: ![]() . (The author is indebted to the reviewers of [13] for this suggestion.)
. (The author is indebted to the reviewers of [13] for this suggestion.)
![]()
![]()
![]()
The inverse algorithm goes like this: Note the total string weight ![]() . Insert a 0 between all letters and then replace the letters
. Insert a 0 between all letters and then replace the letters ![]() , by strings of increasing numbers of 1s:
, by strings of increasing numbers of 1s: ![]() . Add the resulting binary number to
. Add the resulting binary number to ![]() , the number of strings of weight less than
, the number of strings of weight less than ![]() . But wait,
. But wait, ![]() in binary is
in binary is ![]() , and all strings of weight
, and all strings of weight ![]() have been encoded as length
have been encoded as length ![]() binary numbers, so we can add
binary numbers, so we can add ![]() by simply prefixing 1 to the binary number found above. This is reminiscent of the Calkin-Wilf indexing of the rationals, where the index describes a path through the binary tree containing the (positive) rationals.
by simply prefixing 1 to the binary number found above. This is reminiscent of the Calkin-Wilf indexing of the rationals, where the index describes a path through the binary tree containing the (positive) rationals.
![]()
![]()
![]()
![]()
![]()
It appears that RankString functions correctly and gives back the index that generated each string. Here is a slightly longer test.
![]()
![]()
Of course, no finite test can prove that RankString and UnrankString are indeed inverse functions: that claim is based on the unambiguity of the enumeration (strings appear in order of increasing weight, ordered within weight group by composition index). Theoretical considerations [14] indicate that the set of all (finite-length) words that can be formed from a countably infinite alphabet is countably infinite. The above enumeration of all strings is a one-to-one function from the set of all (finite-length) strings onto the set of positive integers and thus provides a direct demonstration that the set is countably infinite.
We use the trivial definition of NextString because it is simpler and almost as efficient as deducing from a given string the next string in the enumeration.
![]()
![]()
![]()
![]()
![]()
In practice it would be faster to iterate on the integer index and convert to the string for use. To use a different alphabet for this enumeration and those that follow, one need only change the definition of characterWeights.
To leave the alphabet unspecified (strings represented as lists of integers), one could remove the line in RankString and StringN (used by UnrankString) that does the replacements, but since one is then enumerating integer compositions, more appropriate names are indicated.

![]()
A New String List Ordering
The string enumeration method described above can be modified to enumerate all lists of strings: Rather than using binary numbers of length ![]() to specify whether commas or pluses are placed between 1s, we can use ternary numbers and let the digits 0, 1, and 2 designate end-of-string, comma (end-of-character), or plus sign, respectively. This generates all possible lists of strings of total weight
to specify whether commas or pluses are placed between 1s, we can use ternary numbers and let the digits 0, 1, and 2 designate end-of-string, comma (end-of-character), or plus sign, respectively. This generates all possible lists of strings of total weight ![]() . Again we must count how many codes are needed for the cases of weight up to
. Again we must count how many codes are needed for the cases of weight up to ![]() and add this to the index within the weight
and add this to the index within the weight ![]() group. Any application that requires all lists of strings of all possible lengths containing all possible characters can use this technique.
group. Any application that requires all lists of strings of all possible lengths containing all possible characters can use this technique.
![]()
![]()
![]()
![]()
Here is a Manipulate window showing the steps in converting an index into a string list.

We wrap this functionality in the function UnrankStringList. It first identifies the weight group ![]() indicated by the index
indicated by the index ![]() (we will offset to make 1 rather than 0 the first index) and then subtracts
(we will offset to make 1 rather than 0 the first index) and then subtracts ![]() from it: this is the index within the weight group and is converted into a list of ternary digits. Starting with
from it: this is the index within the weight group and is converted into a list of ternary digits. Starting with ![]() (to represent a list containing a single string containing only character number 1, A), we scan through the list, taking appropriate action.
(to represent a list containing a single string containing only character number 1, A), we scan through the list, taking appropriate action.
- 0 = end-of-string: end the string and start a new one, by appending
 to ans (a new string A)
to ans (a new string A) - 1 = end-of-character: end the character and start a new one, by appending 1 to the last part of ans (a new character A)
- 2 = increment character: increment the last character of the last string, by adding 1 to the last part of the last part of ans

We reverse the process to recover the index from the string list: first break strings into lists of characters and replace each character by its weight, then construct a ternary code from this list of lists of integers, then add the code found to the number of string lists of smaller weight with an offset to start the index at 1.

Here is how they work.
![]()
![]()
![]()
![]()
In this implementation the functions only recognize the uppercase characters A-Z, but assuming access to some universal character list (not necessarily finite, just countable), all lists of all strings of all characters will appear in our list. Here is an example.
![]()
![]()
![]()
![]()
Empty strings will not appear in the lists generated by UnrankStringList, and should not be included in input for RankStringList. To leave the alphabet unspecified and identify characters by number (weight) only, it is sufficient to remove the lines (first and last, respectively) in the definitions of RankStringList and UnrankStringList that do the replacements based on characterWeights.
A New Ruleset Ordering
Sequential substitution system rulesets can be represented as a list of strings ![]() , with an inferred meaning of
, with an inferred meaning of ![]() , a finite set of string replacement rules. In an SSS, a state string is first scanned for
, a finite set of string replacement rules. In an SSS, a state string is first scanned for ![]() , which if found is replaced by
, which if found is replaced by ![]() . If no substring matching
. If no substring matching ![]() is found, the second replacement rule is invoked, and if needed, the third rule, etc. At each step, only the first possible replacement of the first matching rule is performed. (For more details concerning sequential substitution systems, see Chapter 3, Section 6 of A New Kind of Science [1].)
is found, the second replacement rule is invoked, and if needed, the third rule, etc. At each step, only the first possible replacement of the first matching rule is performed. (For more details concerning sequential substitution systems, see Chapter 3, Section 6 of A New Kind of Science [1].)
If the string list contains an odd number of strings, we have the option of simply throwing away the last string, but that would result in many duplicate rulesets, and there may be a way to use the extra information in the last half rule. One way would be to append a final empty string and thus create in these cases a final rule ![]() . In fact, such “something to nothing” rules, rules that delete a specified substring, are never generated otherwise by the ternary index algorithm, but should be allowed at any position in the ruleset. UnrankString only generated the empty string because of a separate rule defined for the input 0. In the same way, some separate rule or algorithm could be used to insert empty strings in the string list to allow
. In fact, such “something to nothing” rules, rules that delete a specified substring, are never generated otherwise by the ternary index algorithm, but should be allowed at any position in the ruleset. UnrankString only generated the empty string because of a separate rule defined for the input 0. In the same way, some separate rule or algorithm could be used to insert empty strings in the string list to allow ![]() and
and ![]() rules, creating additional rulesets with the same total weight. So our simple list of string lists of a given weight should be extended by the insertion of empty strings—but should they be allowed at all positions? Let us consider the ramifications of including empty strings for a moment.
rules, creating additional rulesets with the same total weight. So our simple list of string lists of a given weight should be extended by the insertion of empty strings—but should they be allowed at all positions? Let us consider the ramifications of including empty strings for a moment.
- As mentioned, “something to nothing” rules simply delete a specified substring. This occurs when an empty string is in an even position in the string list. For completeness we need all possible cases of this type.
- On the other hand “nothing to something” rules, rules of the form
 , will always match at the very beginning of the state string: Look for nothing (we will always find it) and insert a given string there—this is basically an insertion rule. (Note that the insertion always occurs at the beginning of the string, but rules such as
, will always match at the very beginning of the state string: Look for nothing (we will always find it) and insert a given string there—this is basically an insertion rule. (Note that the insertion always occurs at the beginning of the string, but rules such as  effectively cause later insertions.) Now if included, a “nothing to something” rule, an initial insertion rule, should always be the last rule of the ruleset since any following rules would never be invoked. Therefore we only need an empty string at an odd position in the string list when that is the next-to-last position.
effectively cause later insertions.) Now if included, a “nothing to something” rule, an initial insertion rule, should always be the last rule of the ruleset since any following rules would never be invoked. Therefore we only need an empty string at an odd position in the string list when that is the next-to-last position.
It is probably more trouble than it is worth to optionally insert empty strings at only the positions that are “even or next-to-last” in the string list, but these two criteria suggest a simple way to make sure that at least these cases are included while ruling out many of the unwanted cases. Since empty strings never need occur at the beginning of the string list (unless that is in fact the next-to-last position), we will consider inserting an empty string as an alternative way of ending the previous string and starting another (with an empty string inserted between). This will also guarantee that empty strings are not inserted more frequently than every other position, further reducing their occurrence at undesired positions. In order to allow a “something to nothing” rule at the end of the ruleset, if the number of rules is odd we will interpret the final string as such a rule. This method will give some cases with empty strings at odd positions earlier in the list, but we will drop them, and they will occur far less often than if all possible empty string insertions were allowed. It is also trivial to add the new instruction by simply switching to quaternary representation of the index and letting the digits 0, 1, 2, and 3 designate end-string-insert-empty-string-and-start-next-string, end-string-and-start-next-string, comma (end-character-and-start-next-character), or plus sign, respectively. The new instruction forces an immediate end of the previous string, just as does the end-of-string symbol. This generates almost all possible useful sequences of strings of (total sequence) weight ![]() , now including empty strings at all possible positions—except at the beginning of the ruleset. Unfortunately we will get empty strings at some undesired positions, such as in nonfinal
, now including empty strings at all possible positions—except at the beginning of the ruleset. Unfortunately we will get empty strings at some undesired positions, such as in nonfinal ![]() rules, but disallowing them at consecutive positions is good. In any case, the whole point is that we at least get all the cases we want to include automatically. Is that true here?
rules, but disallowing them at consecutive positions is good. In any case, the whole point is that we at least get all the cases we want to include automatically. Is that true here?

Unfortunately not. A little experimentation shows that we easily get “something to nothing” rules both singly and as part of a larger ruleset, but “nothing to something” rules never appear alone. We need some additional way to optionally insert an empty string in the next-to-last position. It is enough to add one extra bit that can be appended to the code.

This does create more duplicates (such as code 1 with extra bit, code 0 without: both give ![]() ), but all the ones we want are there. To create rank and unrank functions we will need to know how many rulesets there are of weight less than
), but all the ones we want are there. To create rank and unrank functions we will need to know how many rulesets there are of weight less than ![]() .
.
![]()
![]()
![]()
![]()
Here is the unrank function.

Notice that rulesets are grouped by total weight. First come the rulesets of weight 1, 2, and 3.
![]()
![]()
![]()
![]()
![]()

Within each weight grouping the rulesets are sorted preferentially to have short strings and secondarily to have low-weight characters early in the string list.
There are some duplicates, but we will be able to discard them when we have an inverse function; if the index is different from the one we started with, it is a duplicate. In any case there will be others to discard as well, rulesets where certain rules will never be invoked—functional duplicates of previous rulesets—that can be discarded out of hand without using them. These include:
- Any case including an identity rule, such as
 . If this rule is ever invoked, it will continue to be invoked thereafter and no further changes will occur.
. If this rule is ever invoked, it will continue to be invoked thereafter and no further changes will occur. - Any case including a nonfinal rule
 . This rule prevents subsequent rules from ever being invoked.
. This rule prevents subsequent rules from ever being invoked. - Any case with two rules with the same left-hand side, such as
 . The second rule will never be invoked and the ruleset will thus be a duplicate of a simpler ruleset.
. The second rule will never be invoked and the ruleset will thus be a duplicate of a simpler ruleset. - Any case with two rules with left-hand sides
 and
and  , such that
, such that  is a substring of
is a substring of  . The second rule will never be invoked and so this ruleset is an effective duplicate.
. The second rule will never be invoked and so this ruleset is an effective duplicate.
In fact, it can be seen that 2 and 3 are special cases of 4. Of course, it would be preferable to generate rulesets that do not include such cases, but it is not immediately obvious how to do so. In any case, much of the redundancy has been eliminated, and what remains is understood and the redundant rulesets identified and skipped over. We have a clear way of iterating through rulesets, although not all of them will be used, and of course, even among those used there will be many duplicate sequential substitution system graphs (from permuting the order of the characters, for instance).

The final line adds the number of rulesets of smaller weights to the reconstructed quaternary code, left-shifts the result, adds the extra bit flag at the end, and finally subtracts 1 in order to start at 1 instead of at 2. Again, other alphabets may be accommodated by adjusting characterWeights, an unspecified alphabet by removing the replacement code.
The following tests the ruleset rank and unrank functions:
![]()
![]()
![]()
![]()
![]()

![]()
![]()
Now we create an increment function to advance to the next (unique and useful) ruleset. Initially we only test whether RankRuleset returns the same index, but we already include the option of additional tests.

![]()
![]()

Here are their indices.
![]()
![]()
Here are the duplicates.
![]()
![]()
![]()
![]()
Yes, these are mostly rulesets with final “something to nothing” rules. Well, it is the price of doing business; the important thing is to include all those needed.
Now we restrict the returned values to rulesets that generate different SSSs by discarding cases with: (1) an identity rule; or (2) two rules with left-hand sides ![]() and
and ![]() , such that
, such that ![]() is a substring of
is a substring of ![]() .
.

Now we can use NextRuleset to iterate through all valid rulesets giving useful SSSs. All problem cases have been eliminated, and all other rulesets will appear somewhere in the list. Here are the first 50.
![]()

Here are their indices.
![]()
![]()
Here are the duplicates and functional duplicates that were skipped.
![]()
![]()
![]()

![]()
![]()
Some are true duplicates (if the index number changed), the others functional duplicates containing rules that will never be invoked in creating a sequential substitution system. This is a manageable situation. Remember, Cantor’s diagonalization contains an infinite number of duplicates of each fraction! The following table summarizes the numbers of unique rulesets and useful (functionally distinct) rulesets for several orders of magnitude. Roughly three-fourths of the generated rulesets are unique, although fewer and fewer of the unique rulesets will give distinct sequential substitution systems.


Conclusion
A review of three methods for enumerating the rational numbers motivated the development of a bijective enumeration of arbitrary-length strings on a countable alphabet of characters (or equivalently, an enumeration of integer compositions). This in turn was extended to form an enumeration of all finite-length sequences of finite-length strings, and an enumeration of all sequential substitution system rulesets. The latter list, although including both exact and functional duplicates, is well defined and relatively dense. Rank, unrank, and successor functions were discussed.
Acknowledgments
My thanks to the NKS Summer School 2009 staff and in particular to Matthew Szudzik for encouraging my interest in enumerations and sequential substitution systems, and to Charles Sarr for his willingness to discuss these ideas at considerable length.
References
| [1] | S. Wolfram, A New Kind of Science, Champaign, IL: Wolfram Media, 2002. |
| [2] | T. Rowland. “Enumerating Strings” from The NKS Forum—A Wolfram Web Resource. (Apr 02, 2010) forum.wolframscience.com/showthread.php?s=&threadid=929. |
| [3] | G. Beck. “A Path through the Lattice Points in a Quadrant” from the Wolfram Demonstrations Project—A Wolfram Web Resource. www.demonstrations.wolfram.com/APathThroughTheLatticePointsInAQuadrant. |
| [4] | D. Bradley. “Counting the Positive Rationals: A Brief Survey.” (Jun 21, 2010) arxiv.org/abs/math/0509025. |
| [5] | Y. Sagher, “Counting the Rationals,” American Mathematical Monthly, 96(9), 1989 p. 823. |
| [6] | N. Calkin and H. Wilf, “Recounting the Rationals,” American Mathematical Monthly, 107(4), 2000 pp. 360-363. www.math.upenn.edu/~wilf/reprints.html. |
| [7] | D. Knuth, C. Rupert, A. Smith, and R. Stong, “Recounting the Rationals, Continued,” American Mathematical Monthly, 110(7), 2003 pp. 642-643. |
| [8] | J. Czyz and W. Self, “The Rationals Are Countable: Euclid’s Proof,” College Mathematics Journal, 34(5), 2003 pp. 367-369. |
| [9] | M. Szudzik. “Enumerating the Rationals” from the Wolfram Demonstrations Project—A Wolfram Web Resource. www.demonstrations.wolfram.com/EnumeratingTheRationals. |
| [10] | B. Yorgey, “Recounting the Rationals, Part II,” The Math Less Traveled (blog), (Apr 2, 2010) www.mathlesstraveled.com/?p=97. |
| [11] | E. Weisstein. “Composition” from Wolfram MathWorld—A Wolfram Web Resource. www.mathworld.wolfram.com/Composition.html. |
| [12] | S. Heubach and T. Mansour, Combinatorics of Compositions and Words, Boca Raton, FL: CRC Press, 2009. |
| [13] | K. Caviness. “Universal String Enumeration” from the Wolfram Demonstrations Project—A Wolfram Web Resource. www.demonstrations.wolfram.com/UniversalStringEnumeration. |
| [14] | R. Kantrowitz, “A Principle of Countability,” Mathematics Magazine, 73(1), 2000 pp. 40-42. |
| K. E. Caviness, “Indexing Strings and Rulesets,” The Mathematica Journal, 2011. dx.doi.org/doi:10.3888/tmj.13-6. | |
About the Author
Ken Caviness teaches physics at Southern Adventist University, a small liberal arts university near Chattanooga, Tennessee. He holds a Ph.D. in physics (emphases in relativity and nuclear physics) from the University of Massachusetts at Lowell, and has taught math and physics in Rwanda, Texas, and Tennessee. His interests include both computer and human languages (including the planned language Esperanto). He has used Mathematica since Version 1, both professionally and for recreational programming.
Kenneth E. Caviness
Physics Department
Southern Adventist University
PO Box 370, Collegedale, TN 37315-0370
caviness@southern.edu